ggplot2 完全解析 EP.01 从 0 到 1

ggplot2 完全解析 EP.01 从 0 到 1
默默杉 & 明明钟ggplot2 完全解析 EP.01 从 0 到 1
视频教程
内容简介
- ggplot2 中会使用到的基本元件
- 使用 ggplot2 需要了解的基本概念
- 不同种类元件的具体用法浅析
- 实例解析 - 小提琴箱线散点图
前言
科研成果的呈现绘图是必不可少的,支持科研图标绘制的工具有很多,比如可视化操作下的 Graphpad Prism、Origin 等等,或者 Python 中的 matplotlib、seaborn、plotly 等等,这些工具我平常也都会用到,主要根据具体环境选择,但是说到生信分析当中的可视化,我还是唯独钟爱 ggplot2,它的简介性、语法一致性、结构完整性、可拓展性都是别的绘图系统不能比的,所以在此开一个坑介绍一下它的各种实际用法。
在讲到具体的各种奇技淫巧之前,还是需要这样一个总起性的章节对这个好用、易用、实用的绘图系统有一个基本的了解
ggplot2 中会使用到的基本元件
- geom 类:geom 是 geometry 的缩写,函数的格式类似
geom_point()/geom_line()/geom_*()等等,主要负责使用原始数据直接绘制各种图形,是一张图标中最主要的部分; - stat 类: stat 是 statistics 的缩写,函数的格式类似
stat_smooth()/stat_qq()/stat_*()等等,负责对原始数据进行统计处理,比如stat_smooth()函数会根据原始数据进行回归分析,并返回预测值,stat_qq()函数会根据原始数据进行 QQ 检验,并返回结果,是在原始数据的基础上进一步进行统计描述; annotate()函数:标注函数,用于在图片上添加自定义注释,比如强调某个点;- scale 类: 函数的格式类似
scale_x_continuous()/scale_y_discrete()/scale_*()等等,负责调整坐标轴、颜色、尺寸、透明度等各种标尺的映射,适当的使用可以使图片更美观或者使需要强调的内容更突出; - 各种主题相关函数:如 theme 类、coord 类、facet 类、guide 类等等,还有
ggtitle()/labs()这些散在的函数,负责调整图片的样式,比如主题风格、坐标轴比例、 分面等等,这些函数的格式类似theme_classic()/coord_polar()/facet_grid()/guide_legend()等等,主要影响图片的美术风格和展示样式,本文主要只对 theme 类稍作展开。
对于 geom 类、stat 类、scale 类,我统称为图形类,因为他们都构成了主图的图形,scale 类我又称为标尺类。对于一张完整的图,图形类的元素是必不可少的,而标尺类与主题类都是锦上添花,而一张完整的图片,就是由这些基本元素排列组合而成的。
ggplot2 的基本概念
代码块的基本构成
首先,我们通常看到的代码块,由各个元件通过 + 号连接构成,比如:
1 | # 遵循 tidyverse 推荐格式 |
很有趣的一点是,ggplot2 在 python 中也得到了几乎完全的移植,如 plotnine,在 python 中,格式略有不同,但是我因为对齐清爽更喜欢这种格式,在 R 语言中也常照搬如下格式:
1 | panel = ( |
输入数据的格式
ggplot2 的输入数据必须是 data.frame 格式,当然,作为 tidyverse 家族的一员,tibble 这种更严格的 data.frame 也是兼容的。
对于 data.frame 这一类表格数据,通常有长表与宽表之分:
长表是指表格的每一行是一个样本,而每一列代表了样本的一个属性,比如:
| id | 颜色 | 大小 | 名称 |
|---|---|---|---|
| 1 | 红 | 大 | 苹果 |
| 2 | 红 | 小 | 樱桃 |
| 3 | 紫 | 大 | 山竹 |
| 4 | 紫 | 小 | 葡萄 |
而宽表内的每一个数据都是一个样本,行名和列名用来定位属性,比如:
| 大小\颜色 | 红 | 紫 |
|---|---|---|
| 大 | 苹果 | 山竹 |
| 小 | 樱桃 | 葡萄 |
在 ggplot2 中,必须使用长表数据,如果你手上的数据是宽表数据也不用担心,有很多种方法可以转换为长表数据,比如 reshape2 包中的 melt() 函数,或者用 tidyr 包中的 pivot_longer() 函数,当然,后者作为 tidyverse 分析流程中的一员,是更为推荐的。
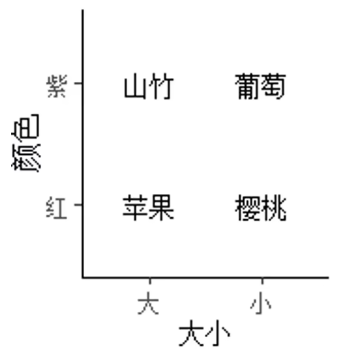
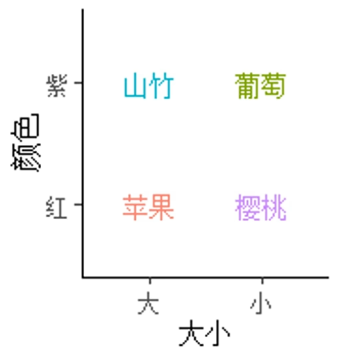
比如我们通过大小为横坐标,颜色为纵坐标,可以把四种水果的标签标记在相应的象限上:
1 | panel <- |
全局数据与局部数据
我们来观察如下两个代码块
1 | panel <- |
1 | panel <- |
在第一个代码块中,所有的数据包括标尺数据都写在 ggplot() 函数中,这代表着之后跟着的所有绘图元素,比如 geom_point()、geom_text(),都会使用 dat 这个数据集进行绘图,我们称为全局数据;在第二个代码块中,数据集 dat1 和 dat2 分别被 geom_point() 和 geom_text() 函数所使用,两种图形依据不同的数据绘制,互不干扰,这被称为局部数据。
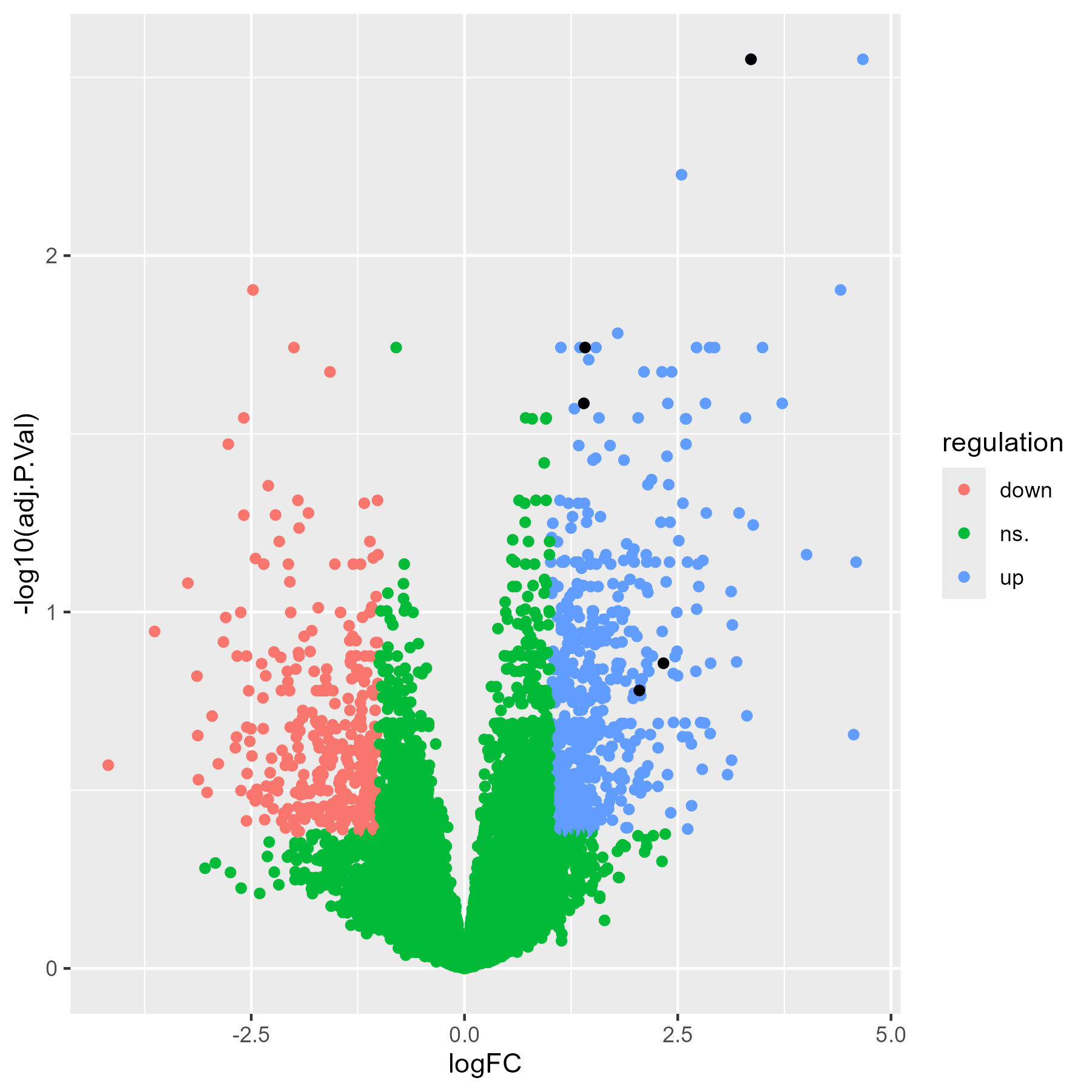
大部分情况下,主图中的内容都写在全局数据中,但是对于一些特殊的标注,就会用到局部数据,比如我们绘制差异基因火山图时,全局数据用于绘制所有基因的散点图,但是对于我们关注的基因,我们就会用局部数据绘制几个单独的点:
1 | panel_volcano <- |
如果只使用全局变量,结果就如下图:
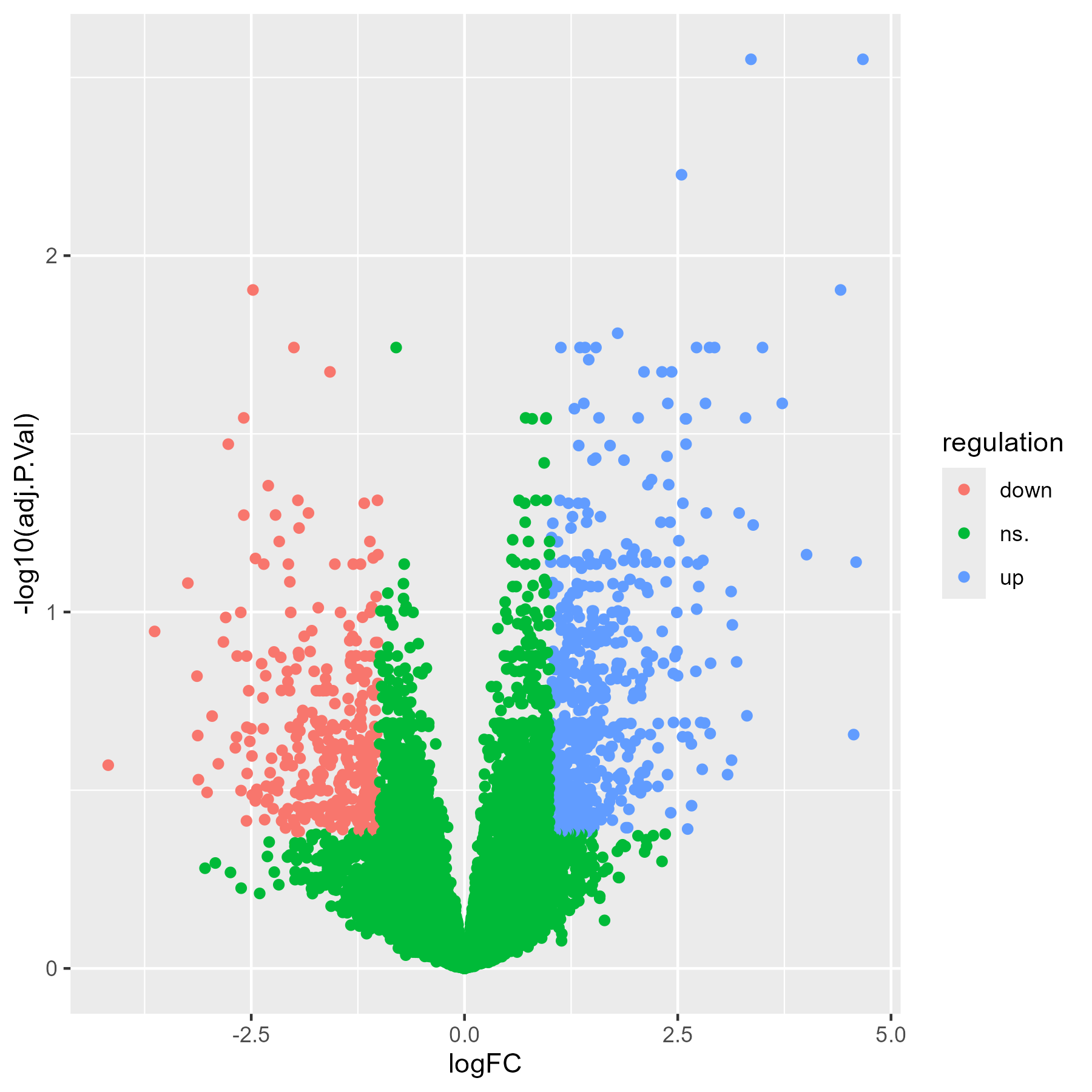
而因为我们添加了局部变量,所以有标记我们关注的基因,如下图:
变量属性与常量属性
我们再观察如下的代码块与对应的图片:
1 | panel <- |
1 | panel <- |
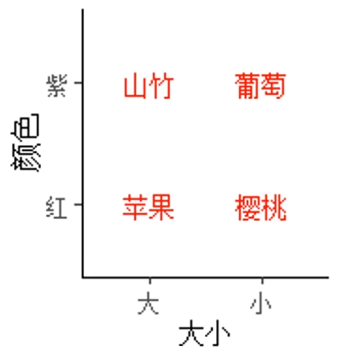
两段代码中,只有 color 属性的位置和值不同,前者 color 放在aes() 内部,基于水果的名称分配绘图颜色,所以每种水果的绘图颜色不同,因而称为变量属性;后者 color 放在 aes() 之外,基于常量值 "red",所以所有水果的绘图颜色都是红色,为常量属性。
变量属性的作用是基于样本的不同属性为绘图元素分配不同外观,比如在通路富集气泡图中根据 p 值的大小分配颜色、根据基因的个数分配点的大小,等等;而常量属性的作用是统一规定图形的外观,比如把图中所有文字的大小都规定为 4。
变量属性与常量属性的区别只在于是否在 aes() 内,切不要与全局数据和局部数据混淆了。
图层
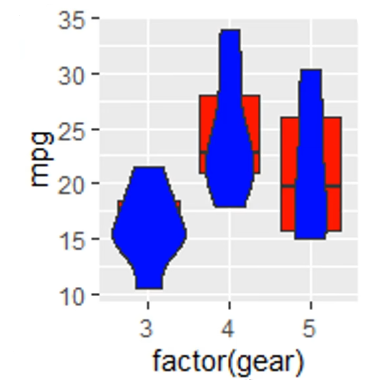
最后我们观察这一对代码块:
1 | panel <- |
1 | panel <- |
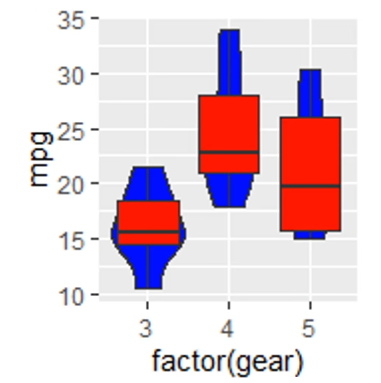
两个示例中,boxplot 与 violin 的顺序不同,因而输出的图片中两种图形覆盖的顺序不同,总而言之,靠后的代码绘制的图形会覆盖靠前的代码绘制的图形。
不同种类元件的具体用法浅析
图形类
以 geom_point() 为例,主要的属性有:
x, y:位置;color:颜色,若为实心形状则为整体颜色,若为空心图形则为边缘颜色;fill:填充颜色,只在空心图形中有效;shape:形状,常用的如 0 为 ■,1 为 ●,22为 □,21 为 ○,等等;size:大小;alpha:透明度,取值范围 0-1,0 表示完全透明,1 表示完全不透明。
这些属性都可用作变量属性或作常量属性。
标尺类
以 scale_color_manual 为例,主要的属性有:
name:名称,显示在图例中,说明颜色标注的是哪个属性;breaks:刻度,与values对应;values:颜色,与breaks对应,规定具体的颜色,比如breaks = c("苹果", "梨"), values = c("red", "blue"),那么苹果的颜色就是红色,梨的颜色就是蓝色;labels:标签,与breaks对应,比如breaks = c("苹果", "梨"), labels = c("apple", "pear"),那么苹果对应的标签就是 apple,梨对应的标签就是 pear。
不同的 scale_*() 函数的具体属性差异巨大,具体还要查阅文档。
主题类
1、 theme 类:ggplot2 提供了各种预设的主题,比如 theme_classic()、theme_bw()、theme_minimal()、theme_void()、theme_gray() 等等,暂不展开自定义主题,以后聊到具体绘图的时候再讲解;
2. labs() 函数:为图形添加标题、图例、坐标轴标签等等,比如 labs(title = "标题", x = "X 轴", y = "Y 轴"),等等;
3. ggtitle() 函数:另一种添加标题的方法,比如 ggtitle("标题"),如果不调整主题,默认显示在图片的左上角。
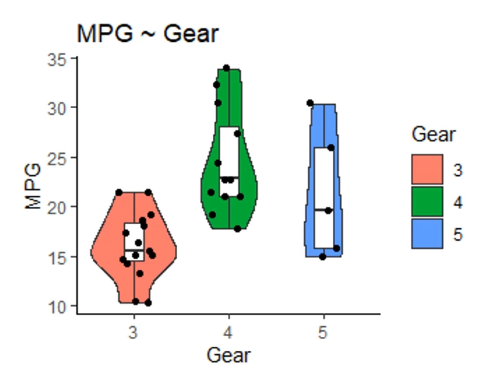
实例解析 - 小提琴箱线散点图
话不多说,直接开画:
1 | panel <- |